Am 27 November bieten wir in Zusammenarbeit mit dem Startpatz Köln einen AI-Workshop im Kölner Mediapark an. Nähere Infos zu Ort und Zeit gibt es hier Artificial Intelligence Workshop
Neben einer generellen Einführung in das Thema Artificial Intelligence werden wir die Historie und aktuelle Anwendungsfälle beleuchten. Danach zeigen wir in einer kurzen Praxis-Session, wie man ein neuronales Netz implementiert.
![]()
Für freuen uns über rege Teilnahme und Diskussionen.
Die Tickets sind kostenfrei aber begrenzt - also bald hier anmelden
Jörg Bienert
Eine Gruppe von Forschern am UCL (University College London) Wissenslabor und Pearson haben ein interessantes KI-Paper über Bildung und die gesamte Transformation von Lernen und Lehren durch Technologie veröffentlicht. Dieses Papier zum Thema „Artificial Intelligence in Education“ AIEd zielt auf zwei Dinge ab. Zum einen wird erklärt, was AIEd ist und wie es aufgebaut ist, zum anderen wird beschrieben, welche Vorteile AIEd hat und wie künstliche Intelligenz die Bildung in den kommenden Jahren positiv verändern wird.
Entscheidend ist, dass die Forscher nicht glauben, dass in Zukunft AIEd die Lehrer ersetzt, sondern daß sich die zukünftige Rolle des Lehrers weiterentwickelt und schließlich transformiert wird.
Die Schlussfolgerung der Wissnschaftler ist, dass AIEd in gemischten Lernräumen eingesetzt wird, in denen computergesteuerte Lehrinhalte und Übungen sich gegenseitig ergänzen.

Am 23.November 2017 findet in Köln der Kongress „IoT-Future Trends“ statt, veranstaltet vom eco-Verband und der IHK Köln.
Zentrales Thema ist, wie man die riesigen Datenmengen, die im Internet of Things entstehen, mit Hilfe von Künstlicher Intelligenz, Deep-Learning- und weiteren Verfahren sinnvoll auswerten und nutzbar machen kann.

Ich freue mich, dort einen Vortrag über den Einsatz von künstlicher Intelligenz halten zu dürfen und habe vorab bereits ein Interview gegeben.
Der Eco-Verband hat uns zwei Frei-Tickets zur Verfügung gestellt, die wir hier gerne im Rahmen einer Verlosung weitergeben möchten.
Interessenten schicken uns bitte ein kurzes E-Mail an Tickets@aiso-lab.de
Wir sehen uns in Köln!
Jörg Bienert
Vor einem Jahr veröffentlichte Google im Jama Netzwerk einen Artikel zum Thema " Entwicklung und Validierung eines tiefliegenden Algorithmus zur Erkennung von diabetischer ". Dort wurde nachgewiesen, dass eine der Hauptursachen für Blindheit die diabetische Retinopathie (DR) ist, bei der Schäden an der Netzhaut durch Diabetes auftritt.
Google Brain, das KI Team von Google, hat mit Medizinern zusammengearbeitet und mehr als 128.000 Bilder gesammelt, die von jeweils 3-7 Augenärzten. Auf Basis dieser Bilder wurden ein Deep-Learning Algorithmus entwickelt, um ein Modell zur Erkennung der diabetischen Retinopathie zu erstellen. Die Durchführung der Berechnung wurde an zwei unterschiedlichen Datensätzen mit insgesamt 12.000 Bildern getestet.
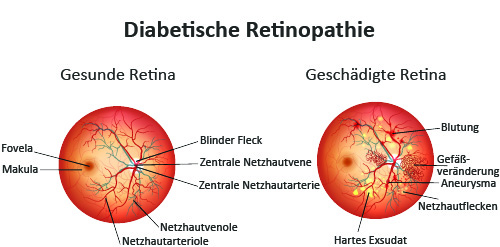
Der Einsatz von Maschine Learning (ML) bei der diabetischen Retinopathie ist ein Fortschritt in den Bereichen künstliche Intelligenz und Gesundheitsfürsorge. Die automatische Diagnose der DR mit höherer Genauigkeit kann Augenarztpraxen dabei helfen, mehr Patienten zu bewerten und die Behandlung zu optimieren
Im vergangenen Jahr war AlphaGo das erste Programm, das einen Weltmeister im Go-Spiel besiegte. AlphaGo wertete Positionen aus und selektierte Bewegungen mit Hilfe von tiefen neuronalen Netzwerken. Diese neuronalen Netze wurden durch das Lernen von ungefähr 1000 historischen Partien von Go-Meistern trainiert. Hierauf folgte eine Lernphase, in der der Rechner 1 Millionen mal gegen sich selber spielte.
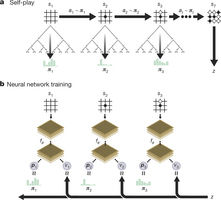
Abbildung 1: Selbstspielendes Verstärkungslernen in AlphaGo Zero.
Googles Deep Mind Tean hat nun ein verbessertes neues System, Alpha Go Zero, vorgestellt, das dem „alten“ um Längen überlegen ist. Neben Änderungen im Algorithmus und der Netz-Architektur ist vor allem erstaunlich, dass dieses Netz ohne die Hinzunahme von existierenden „menschlichen“ Partien trainiert wurde.
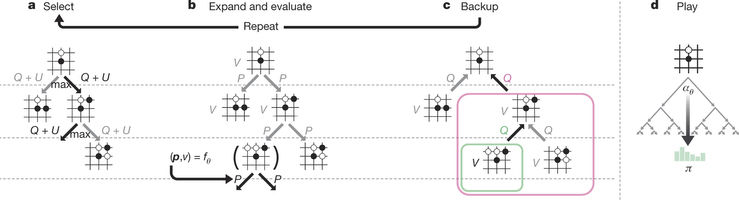 Abbildung 2: MCTS in AlphaGo Zero
Abbildung 2: MCTS in AlphaGo Zero
Die Ergebnisse von Alphago Zero zeigen, dass ein reiner Ansatz über Reinforcement-Learning auch in den schwierigsten Bereichen durchaus erfolgreich ist, wobei sich die reine Trainingszeit gegenüber dem alten Alphago nicht signifikant erhöht hat.
Ergebnis:
Training ohne Experten-Know-How : Training auf Basis von menschlichem Wissen = 100:0
Zur Beschleunigung der Alzheimer Diagnose entwickelten Forscher der Universität Bari in Italien eine künstliche Intelligenz, um strukturelle Veränderungen im Gehirn zu erkennen, die durch die-Krankheit verursacht wurden. Zunächst trainierten sie den Algorithmus mit 67 MRT-Scans (Magnetresonanztomographie), von 38 von Menschen mit Alzheimer und von 29 gesunden Kontrollpersonen. Die Scans stammen aus der Datenbank der Alzheimer Disease Neuroimaging Initiative der Universität von Southern California in Los Angeles.
Die Wissenschaftler haben einen ausgeklügelten Algorithmus entwickelt, der die MRT-Scans analysiert und die Veränderungen im Gehirn mit einer Genauigkeit von mehr als 80 Prozent registriert.
Eine Heilung gibt es zur Zeit bei Alzheimer nicht, aber eine frühe Diagnose bedeutet, dass die Patienten schneller behandelt werden. Ärzte verwenden bereits seit einiger Zeit MRT-Scans, um nach Veränderungen im Gehirn zu suchen, die für Alzheimer charakteristisch sind, aber die Informatiker sind überzeugt, dass das trainierte neuronale Netz die Diagnosen unterstützen kann, sogar bevor Unterschiede direkt sichtbar werden. Nach Aussage der Wissenschaftler kann diese Innovation innerhalb von zehn Jahren zur Vorbeugung von Alzheimer und anderen Krankheiten eingesetzt werden.
Das AICamp in Frankfurt folgt der Tradition der seit 2009 stattfindenden Cloudcamps und bietet im „Unkonferenz-Format“ Vorträge und Diskussionen im OpenSpace.
Das erste Event findet am 25.10.2017 in der Frankfurt University of Applied Science statt. Hier gibt es weitere Infos und Anmeldemöglichkeiten.
Ich freue mich darüber die "7 Herausforderungen bei AI Projekten" präsentieren zu dürfen und bin gespannt auf die anschliessenden Diskussionen.
Jörg Bienert

Ein Team von Wissenschaftlern der Universität New York hat eine neue skalierbare, sliding-Window Lösung gezeigt, die für die Klassifizierung, Erkennung und Lokalisierung von Bildern genutzt werden kann. Im Test mit ILSVRC-Datensätzen erzielte dieses Verfahren im Vergleich mit anderen Algorithmen Platz 1 in der Erkennung und Lokalisierung sowie den 4. Platz in der Erkennung von Bildern.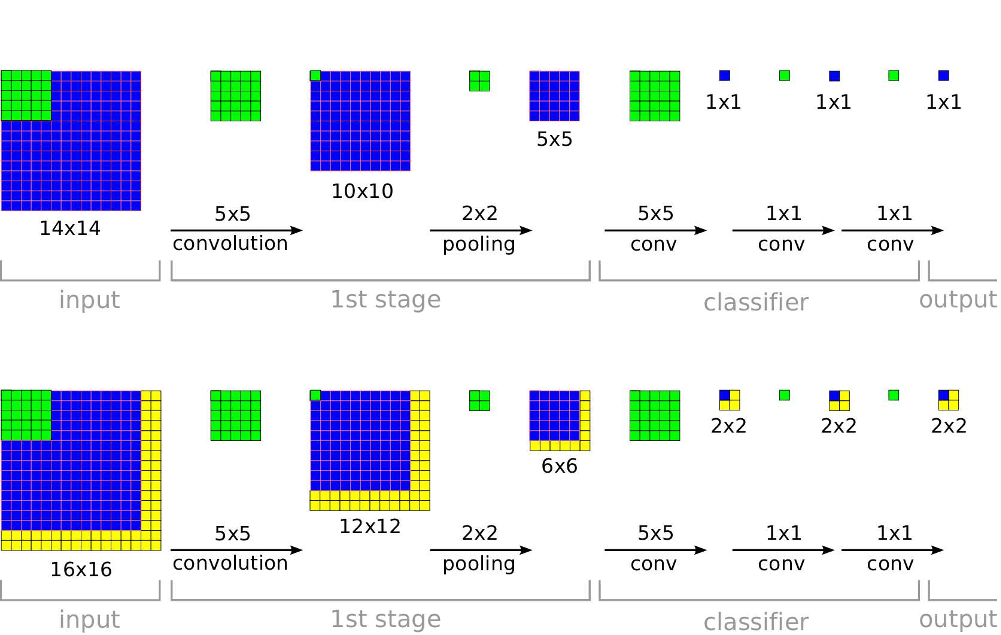 Quelle: https://arxiv.org/pdf/1312.6229.pdf
Quelle: https://arxiv.org/pdf/1312.6229.pdf
Ein weiterer wichtiger Aspekt in dieser Studie behandelt die Frage, wie ConvNets effektiv für solche Erkennungs- und Lokalisierungsaufgaben eingesetzt werden können, die nie vorher nicht erkannt wurden. Das Team um Pierre Sermanet und AI-Ikone Yann LeCun, ist daher das erste, das klärt, wie dies in Bezug auf ImageNet möglich sein könnte. Die vorgeschlagene Architektur enthält wesentliche Änderungen am der Struktur des neuronalen Netzes. Zusätzlich wird anhand dieses Ansatzes gezeigt, wie verschiedene Aufgaben mit einem gemeinsamen Netzwerk gleichzeitig erlernt werden können
Der Begriff künstliche Intelligenz (englisch: artificial intelligence, kurz A.I.) bezeichnet die Untersuchung und das Design intelligenter Verhaltensweisen von Maschinen. In seiner modernen Form entstand das Feld in den Fünfzigerjahren. In dieser frühen Phase herrschte – wie zur selben Zeit auch in anderen technologischen Bereichen – ein erheblicher Optimismus, dessen Versprechen aber in den folgenden Jahrzehnten nicht gehalten werden konnten. Abgesehen von grundsätzlichen Problemen wie der Fragen, was genau eigentlich Intelligenz ist und wie sie sich erkennen lässt, blieben konkrete Erfolge beim Entwurf glaubhaft intelligenter Systeme aus.
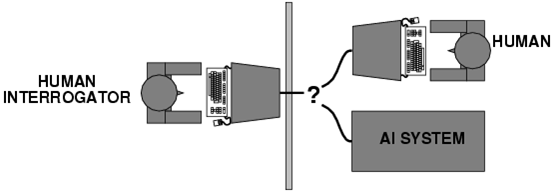
Kennzeichnend für diese neu entstandene Skepsis ist die wissenschaftliche Debatte, die sich rund um die Frage entwickelte, wie sich Intelligenz von Maschinen überhaupt nachweisen lasse. Bereits 1950 hatte Alan Turing den nach ihm benannten Turing Test vorgeschlagen. Bei diesem Test kommuniziert eine Testperson über einen Fernschreiber (Computerterminals gab es zu Turings Zeiten noch nicht) mit einem Gegenüber, von dem sie nicht weiß, ob es ein Computer oder ein Mensch ist. Wenn der Gesprächspartner ein Computer ist und die Testperson ihn dennoch als Mensch identifiziert, wäre dies, so Turing, der Beweis für die Intelligenz der Maschine.
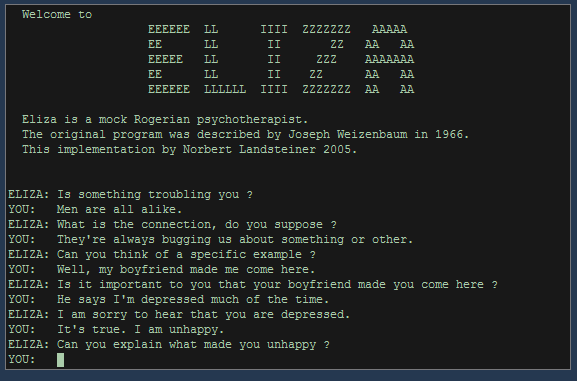
Die Methode des Turing Tests wurde im weiteren Verlauf der Debatte mehrfach kritisiert. In den Sechzigerjahren schuf Joseph Weizenbaum das Programm ELIZA, das nach heutigen Maßstäben recht einfach strukturiert war und einen Gesprächspartner in verschiedenen Rollen simulieren konnte. Zu Weizenbaums eigener Verblüffung gelang es ELIZA – vor allem in ihrer Rolle als Psychotherapeut – immer wieder, ihre menschlichen Gesprächspartner zu „täuschen“. Der pseudo-therapeutische Kontext legte allerdings auch nahe, dass es sich hierbei zumindest zum Teil auch um Projektion auf menschlicher Seite handelte: Die Testpersonen interpretierten mehr in die Äußerungen von ELIZA hinein, als wirklich zu lesen war.
Auch von philosophischer Seite gab es Einwände: 1980 entwarf John Searle das Chinese room argument. Bei diesem Gedankenexperiment befindet sich ein Mensch ohne Kenntnis der chinesischen Sprache im Kontext eines Turing Tests in einem Raum, ausgestattet mit allen erdenklichen Büchern und Ressourcen zur chinesischen Sprache und Kultur. Eine andere Person reicht diesem Menschen nun Fragen auf Chinesisch ein und erhält Antworten auf Chinesisch zurück. Searles Argument ist nun, dass der Mensch im chinesischen Zimmer Fragen lesen und beantworten kann, ohne auch nur ein Wort Chinesisch zu „verstehen“. Er ist damit in derselben Situation wie ein Computer, der vom menschlichen Nutzer Anfragen erhält und beantwortet (auf Chinesisch oder nicht). Die Maschine „versteht“ nicht, was vor sich geht, sie arbeitet lediglich auf Basis syntaktischer Regeln ohne Einblick in die Bedeutung ihres Inhaltes. Natürlich lassen sich gegen Searles Gedankenexperiment linguistische und sinologische Einwände erheben, aber es wirft eine sehr grundsätzliche Frage auf: Sind Intelligenz und Kommunikation reine Symbolverarbeitung auf syntaktischer Basis, oder gibt es so etwas wie eine tiefere semantische Ebene von Inhalt und Bedeutung?
Vor derart grundsätzliche Probleme gestellt, begannen sich Forschung und Entwicklung im Bereich künstlicher Intelligenz in zwei Hauptstränge aufzuteilen: Vorerst im Hintergrund blieb der Bereich der Artificial general intelligence, also der Entwurf von Maschinen, die sich aller erdenklichen Aufgaben mit intelligenten Methoden annehmen können. Verwandt, aber utopischer ist die strong A.I., die den exakten Nachbau menschlicher Intelligenz auf maschineller Basis anstrebt. Entscheidend ist hierbei, dass ein solcher Nachbau dem Vorbild gleichgesetzt wäre – die Simulation wäre dann mit dem Original identisch.
Wesentlich erfolgreicher operiert seit Längerem das Feld der narrow A.I., auch weak A.I. oder applied A.I. Hier wird maschinelle Intelligenz nur in eingeschränkten und spezialisierten Gebieten betrachtet. Beispiele hierfür sind:
- Problemlösungsstrategien
- Data-Mining
- Maschinelles Lernen
- Robotik
- Spracherkennung
- Schließen und Entscheiden auf der Basis unsicherer oder unscharfer Information
- Sehen und Mustererkennung
Viele dieser Gebiete haben in den letzten Jahrzehnten große Fortschritte erzielt. Suchmaschinen beherrschen Data-Mining und unscharfe Suchstrategien, mobile Assistenten in Smartphones erkennen das gesprochene Wort ihrer Benutzer fast fehlerfrei und greifen ihrerseits nahtlos auf Suchmaschinen zurück. Die Robotik hat sich zu einem Teilgebiet der künstlichen Intelligenz gemausert unter der Annahme, dass fundiertes Weltwissen als Grundlage von intelligentem Denken und Handeln nur durch physischen Kontakt mit der Wirklichkeit zustande kommen kann.
Die künstliche Intelligenz hat also einen weiten Weg zurückgelegt. Zwar kommuniziert man mit mobile Assistenten heute wie mit einem Menschen, aber die grundsätzlichen Fragen zur Intelligenz und zur Unterscheidung von Original und Simulation, syntaktischer Symbolverarbeitung und semantischem Verständnis, sind nach wie vor offen.
Während neuronale Netze derzeit in der Regel als Softwareimplementierungen auf klassichen CPU oder GPU Architekturen ablaufen, geht Intel mit der neuesten Entwicklung einen Schritt weiter und stellt einen „Neuromorphic“ Chip vor.
Der Loihi-Chip hat 1.024 künstliche Neuronen oder 130.000 simulierte Neuronen mit 130 Millionen möglichen synaptischen Verbindungen. Das entspricht ungefähr der Komplexität eines Hummers, ist aber weit entfernt von den 80 Milliarden Neuronen eines menschlichen Gehirns. Der Lernprozess erfolgt direkt auf dem Chip, der damit bis zu 1.000 fach schneller sein soll als herkömmliche prozessorgesteuerte Verfahren.
Für die praktische Anwendung ist die Entwicklung von entsprechenden Algorithmen erforderlich. Hierfür wird der Chip Anfang 2018 zunächst an Universitäten und Forschungseinrichtungen ausgeliefert.
