Im vergangenen Jahr war AlphaGo das erste Programm, das einen Weltmeister im Go-Spiel besiegte. AlphaGo wertete Positionen aus und selektierte Bewegungen mit Hilfe von tiefen neuronalen Netzwerken. Diese neuronalen Netze wurden durch das Lernen von ungefähr 1000 historischen Partien von Go-Meistern trainiert. Hierauf folgte eine Lernphase, in der der Rechner 1 Millionen mal gegen sich selber spielte.
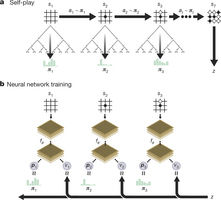
Abbildung 1: Selbstspielendes Verstärkungslernen in AlphaGo Zero.
Googles Deep Mind Tean hat nun ein verbessertes neues System, Alpha Go Zero, vorgestellt, das dem „alten“ um Längen überlegen ist. Neben Änderungen im Algorithmus und der Netz-Architektur ist vor allem erstaunlich, dass dieses Netz ohne die Hinzunahme von existierenden „menschlichen“ Partien trainiert wurde.
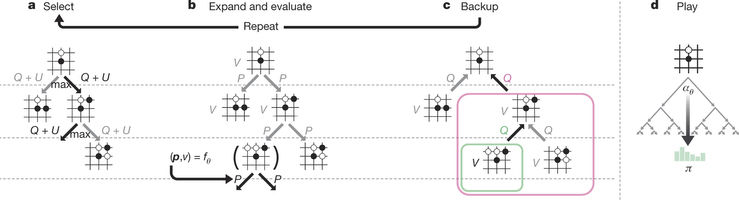 Abbildung 2: MCTS in AlphaGo Zero
Abbildung 2: MCTS in AlphaGo Zero
Die Ergebnisse von Alphago Zero zeigen, dass ein reiner Ansatz über Reinforcement-Learning auch in den schwierigsten Bereichen durchaus erfolgreich ist, wobei sich die reine Trainingszeit gegenüber dem alten Alphago nicht signifikant erhöht hat.
Ergebnis:
Training ohne Experten-Know-How : Training auf Basis von menschlichem Wissen = 100:0
Zurück