On 27th of November, the Artificial Intelligence Workshop will take place at Startplatz in Köln.
Are you an early bird? Then click here to get FREE TICKETS and find additional information here.
![]()
The main topics of this workshop include interactive presentations of AI but also open discussion about technology, applications, social impact and more.
I am looking forward to seeing you there!
Jörg Bienert
A group of researchers at the UCL (University College London) Knowledge Lab and Pearson have published an interesting AI paper regarding Education and the overall transformation of learning and teaching through technology. This paper aims at two things: the first is to explain what AIEd is and how it is built, and the second is to find out what the benefits of AIEd and how artificial intelligence will positively transform education in the coming years.
This approach describes how adequately designed and well-thought-out AIEd implementation can successfully contribute to the classroom environment. Importantly, the researchers do not see AIEd replacing teachers; instead, the future role of teachers continues to evolve and is eventually transformed such that their time is used more efficiently.
The researchers’ conclude that AIEd should be implemented in mixed learning environments where computerised advances and customary classroom exercises supplement each other. Understanding this implies tending to the 'chaos' of genuine classrooms, colleges, or workplace learning conditions, and including teachers and students in the application of AIEd with the goal that the outline would resemble this:

On 23rd November 2017, the conference "IoT Future Trends" will take place, hosted by the eco-Verband and IHK Köln.
The central topic is how to intelligently use and evaluate the enormous amounts of data generated in the “Internet of things” with the help of artificial intelligence, deep-learning, and other methods.

I am delighted to give a lecture regarding the use of artificial intelligence there - while I have already given an interview in advance.
The Eco-Association has provided us two free tickets, which we would like to offer you as part of a raffle.
Please send us a short e-mail to Tickets@aiso-lab.de
See you soon in Cologne!
Jörg Bienert
A year ago Google published a paper on " Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs" at The Jama Network. It demonstrated that one of the main reasons for blindness is Diabetic Retinopathy (DR), a medicinal condition in which harm occurs to the retina because of diabetes.
Google Brain, the company’s AI team, has worked with specialists to enable them to analyse DR. The group has gathered more than 128,000 pictures that were each assessed by 3-7 ophthalmologists. These images were processed by a deep learning algorithm for making a model to recognise Diabetic Retinopathy. The execution of the calculation was tested on two distinctive datasets totalling to 12,000 images.
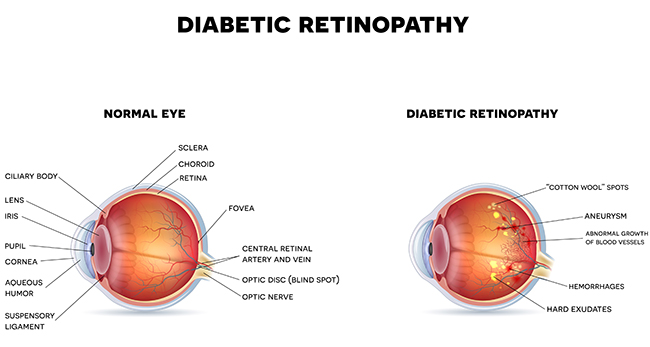
The use of Machine Learning (ML) in Diabetic Retinopathy is a leap forward in the fields of AI and health care. Robotized diagnosis of DR with higher exactness can help eye doctor's facilities in evaluating more patients and prioritising the treatment. This innovation can fill the existing deficiency in ophthalmology divisions.
Last year, AlphaGo became the first program to defeat a world champion in the game of Go. The tree search in AlphaGo evaluated positions and selected moves using deep neural networks. These neural networks were trained by supervised learning from human expert moves, and by reinforcement learning from self-play. The latest version of the computer program, named AlphaGo Zero, is the first to master Go, without human guidance.
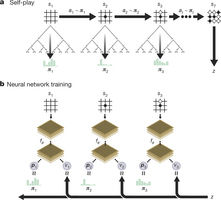
Figure1: Self-playing reinforcement learning in AlphaGo zero
Google Deep mind researchers have presented an algorithm based exclusively on reinforcement learning, without human data, support or knowledge beyond gaming rules. AlphaGo turns into its own teacher: a neural system is trained to predict AlphaGo's move selections, and it is taught solely through self-play, starting with entirely random moves.
This neural network enhances the quality of the tree search by bringing higher quality move selection and more grounded self-play in the following cycle. Starting tabula rasa, the new program AlphaGo Zero accomplished superhuman performance, winning 100 – 0 against the previously published, champion-crushing AlphaGo
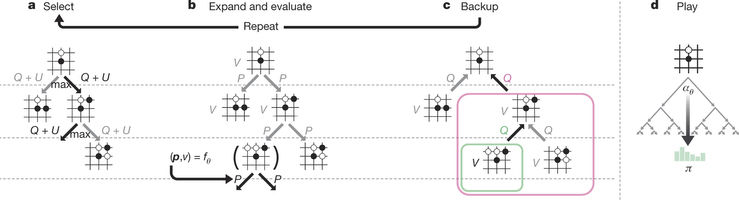
Figure2: MCTS in AlphaGo Zero
The outcomes from this algorithm demonstrate that a pure reinforcement learning approach is completely feasible, even in the most challenging areas. Besides, this approach requires only a couple of more hours to train and accomplishes much better asymptotic performance, compared to preparation on human expert data.
To empower prior diagnosis, researchers at the University of Bari in Italy developed a machine-learning calculation to recognize structural changes in the brain caused by Alzheimer's disease. First, they trained the algorithm using 67 MRI (Magnetic Resonance Imaging) scans, 38 of which were from people who had Alzheimer’s and 29 from healthy controls. The scans came from the Alzheimer’s Disease Neuroimaging Initiative database at the University of Southern California in Los Angeles.
Scientists have created a sophisticated algorithm that analyses MRI scans and notes structural changes to the mind caused by the disease, with an accuracy of more than 80 percent. This complex algorithm can distinguish the brains of healthy subjects from those with Alzheimer's with 86% precision. It could likewise recognize stable patients from those with MCI (Mild Cognitive Impairment) with 84% precision.
At present, there is no cure for Alzheimer; however early diagnosis implies that patients can get treatment sooner and can make more care arrangements. Doctors already use MRI scans to look for changes characteristic of Alzheimer's, but scientists believe artificial intelligence could help specialists to diagnose the conditions before differences are visible. Researchers think that this innovation could be used to foresee Alzheimer's and other diseases within ten years.
The AICamp “Unconference” in Frankfurt follows the tradition of the Cloud Camps which have been taking place since 2009 and offer lectures and discussions.
The first event will take place on October 25, 2017, at the Frankfurt University of Applied Science. You can find further information on the following link and for registration click here.
I will talk about the "7 challenges of AI project"s and am looking forward to inspiring discussions afterwards.
Joerg Bienert

A team of scientists at the University of New York has developed a new multi-scale, sliding window approach that can be utilized for image classification, detection, and localization. This approach in comparison to others based on the ILSVRC datasets, ranked 4th in classification, 1st in localization and 1st in detection. 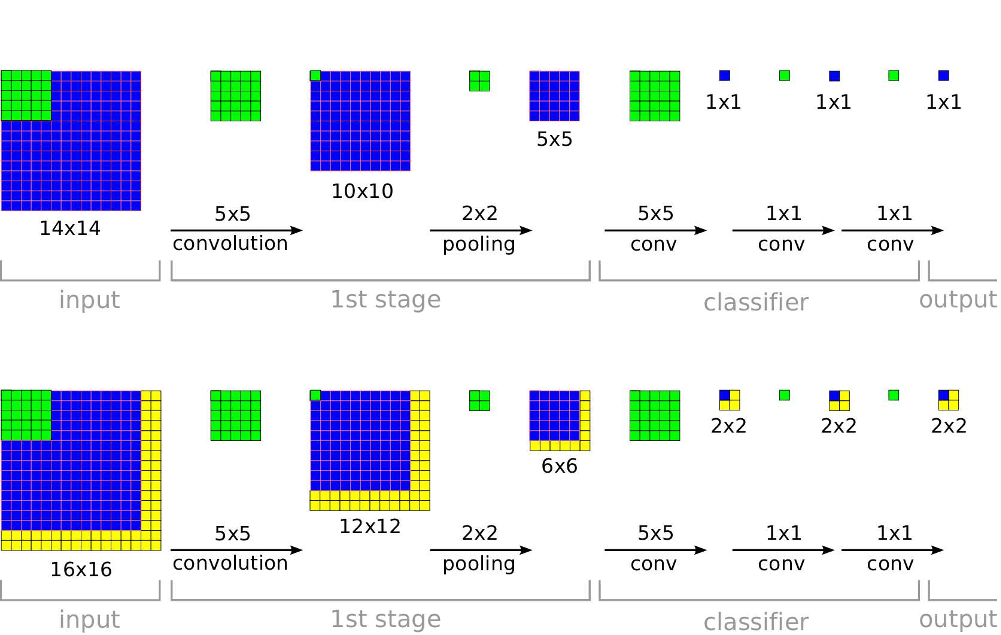
Source: https://arxiv.org/pdf/1312.6229.pdf
Another important contribution in this paper is the clarification of how ConvNets can be effectively used for detection and localization tasks. This team is the first to clarify how this could be achieved with regards to ImageNet. This proposed plot includes substantial modifications to the neural network design for classification. Also, through this approach, it is shown how different tasks can be learned simultaneously by using a single shared network.
The term Artificial Intelligence (short-term A.I.) refers to the investigation and the design of the intelligent behavior of the machines. The modern form of the field was developed in the fifties and at this early stage, while a considerable optimism was noticed also in other technological areas, its promise did not remain sustainable during the following decades. Fundamental problems questioning the Artificial Intelligence meaning and its perception were distinguished. However, concrete successes in the credible intelligent systems design were achieved too.
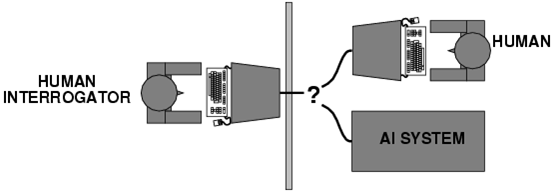
A characteristic of this new skepticism is the scientific debate which later on developed the question of how the machine intelligence can be demonstrated at all. In the early 1950s, Alan Turing proposed the Turing test which was named after him. In this test, a person communicates via a telegraph with a counterpart that does not know whether it is a computer or a human being. If the interlocutor is a computer and the test person nevertheless identifies it as a human being, then this effect according to Turing would be a proof of the machine intelligence.
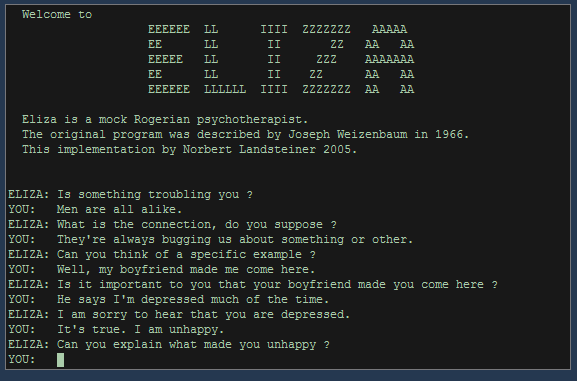
The method of this test was criticized several times in the debate. Consequently, in the 1960s Joseph Weizenbaum created the ELIZA program which according to today’s standards was quite simply structured and could simulate a partner conversation in various roles. ELIZA – especially in the role as a psychotherapist – repeatedly managed to “deceive” the human partner conversation with regard to Weizenbaum’s own bemusement. Later on, the pseudo-therapeutic context also suggested that this was at least partly a projection on the human side: the individual tests were interpreted more in the ELIZA’s observations than were actually meant to be read.
There were also objections from a philosophical point of view: in 1980 John Searle designed the Chinese room argument. In this experiment, a person who had no knowledge of the Chinese language would take part. The individual would be in the context of a Turing test within a room equipped with all imaginable books and resources in Chinese language and culture. Another individual would then ask the test subject questions in Chinese and receive answers in Chinese. Searle’s argument is that people in the Chinese room could read and answer questions without “understanding” a word in Chinese. Thus, we can notice here the same situation like a computer that receives and responds to the human user (in Chinese or not).
The machine does not “understand” what is going on, it only works on the basis of syntactic rules without an insight into its content meaning. Of course, against Searle’s thought experiment, linguistic and cynological objections can be asked. However, here it is raised a fundamental question: is intelligence and communication pure symbol processing on a syntactic basis or is there something of a deeper semantic level of content and meaning?
Before such fundamental problems were observed, research and development in the field of Artificial Intelligence began to be divided into two main strands: the background of the Artificial General Intelligence field, that is, the design of machines - which can assume all conceivable tasks with intelligent methods. But the utmost is the strong AI, which strives for the exact reproduction of human intelligence on a machine basis. The decisive factor here is that if such a replica would be equivalent to the model, the simulation would then be identical with the original.
The field of the narrow A.I. has been successful for a long time, as well as the weak A.I. or applied A.I.
Here, machine intelligence is only considered in restricted and specialized areas. Examples for this are:
- Problem-solving strategies
- Data-Mining
- Machine learning
- Robotics
- Speech recognition
- Closing and deciding on the basis of unsafe or blurred information
- Showing and pattern recognition
In recent decades, many of these areas have made great progress. Search engines, master data mining, blurred search strategies and mobile wizards in smartphones recognize the spoken word of their users almost flawlessly and access their search engines seamlessly. Robotics has become a part of the artificial intelligence. Assuming the founded global knowledge as the basis of intelligent thinking as well as the actions that can only come about through physical contact with reality.
The artificial intelligence has therefore travelled a long way. While mobile assistants are now communicating with human beings, the fundamental questions about intelligence and the distinction between the simulation, syntactic symbol processing, and semantic understanding are still open.
While neural networks currently run as software implementations on classic CPU or GPU architectures, Intel goes one step further with the it’s latest development and introduces a "neuromorphic" chip.
The Loihi chip has 1,024 artificial neurons or 130,000 simulated neurons with 130 million possible synaptic connections. This is roughly the same complexity as a lobster’s brain, but is far from the 80 billion neurons of a human brain. The learning process is executed directly on the chip, which is supposed to be up to 1,000 times faster than conventional processor-controlled architectures.
The development of appropriate algorithms is necessary for practical application. Therefore, the chip will initially be delivered to Universities and research Institutes at the beginning of 2018.
