AI News AlphaGo Zero: Better Go without human knowledge
Last year, AlphaGo became the first program to defeat a world champion in the game of Go. The tree search in AlphaGo evaluated positions and selected moves using deep neural networks. These neural networks were trained by supervised learning from human expert moves, and by reinforcement learning from self-play. The latest version of the computer program, named AlphaGo Zero, is the first to master Go, without human guidance.
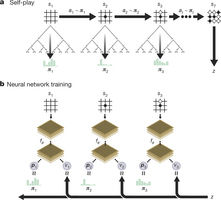
Figure1: Self-playing reinforcement learning in AlphaGo zero
Google Deep mind researchers have presented an algorithm based exclusively on reinforcement learning, without human data, support or knowledge beyond gaming rules. AlphaGo turns into its own teacher: a neural system is trained to predict AlphaGo’s move selections, and it is taught solely through self-play, starting with entirely random moves.
This neural network enhances the quality of the tree search by bringing higher quality move selection and more grounded self-play in the following cycle. Starting tabula rasa, the new program AlphaGo Zero accomplished superhuman performance, winning 100 – 0 against the previously published, champion-crushing AlphaGo
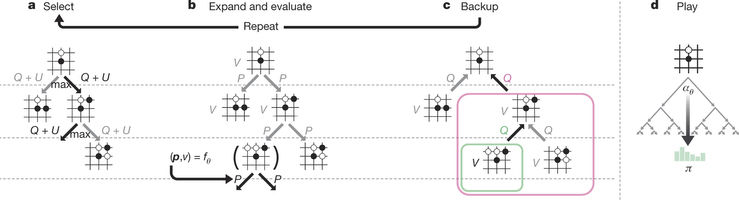
Figure2: MCTS in AlphaGo Zero
The outcomes from this algorithm demonstrate that a pure reinforcement learning approach is completely feasible, even in the most challenging areas. Besides, this approach requires only a couple of more hours to train and accomplishes much better asymptotic performance, compared to preparation on human expert data.
Zurück